






Intervalo de referência

Content
Definição padrão
A definição padrão de um intervalo de referência para uma medição específica é definida como o intervalo entre os quais 95% dos valores de uma população de referência se enquadram, de tal maneira que 2,5% das vezes um valor será menor que o limite inferior disso intervalo e 2,5% do tempo será maior que o limite superior desse intervalo, qualquer que seja a distribuição desses valores.
Os intervalos de referência que são fornecidos por essa definição às vezes são referidos como faixas padrão.
Em relação à população -alvo, se não for especificada de outra forma, um intervalo de referência padrão geralmente denota aquele em indivíduos saudáveis, ou sem qualquer condição conhecida que afete diretamente os intervalos estabelecidos. Eles também são estabelecidos usando grupos de referência da população saudável e às vezes são denominados intervalos normais ou valores normais (e às vezes intervalos/valores "usuais"). No entanto, o uso do termo normal pode não ser apropriado, pois nem todos fora do intervalo são anormais, e as pessoas que têm uma condição específica ainda podem se enquadrar nesse intervalo.
No entanto, os intervalos de referência também podem ser estabelecidos colhendo amostras de toda a população, com ou sem doenças e condições. Em alguns casos, indivíduos doentes são tomados como população, estabelecendo faixas de referência entre aqueles que têm uma doença ou condição. De preferência, deve haver faixas de referência específicas para cada subgrupo da população que tem algum fator que afete a medição, como, por exemplo, intervalos específicos para cada sexo, faixa etária, raça ou qualquer outro determinante geral.
Métodos de estabelecimento
Os métodos para estabelecer intervalos de referência podem ser baseados em assumir uma distribuição normal ou uma distribuição log-normal, ou diretamente das porcentagens de interesse, conforme detalhado, respectivamente, nas seções a seguir. Ao estabelecer variações de referência de órgãos bilaterais (por exemplo, visão ou audição), ambos os resultados do mesmo indivíduo podem ser usados, embora a correlação intra-sujeito deva ser levada em consideração.
Normal distribution O intervalo de 95% é frequentemente estimado assumindo uma distribuição normal do parâmetro medido; nesse caso, pode ser definido como o intervalo limitado em 1,96 (geralmente arredondado até 2) desvios padrão da população de ambos os lados da média da população (também chamado de valor esperado). No entanto, no mundo real, nem a população significa nem o desvio padrão da população. Ambos precisam ser estimados em uma amostra, cujo tamanho pode ser designado n. O desvio padrão da população é estimado pelo desvio padrão da amostra e a média da população é estimada pela média da amostra (também chamada média ou média aritmética). Para explicar essas estimativas, o intervalo de previsão de 95% (95% PI) é calculado como:
95% PI = mean ± t0.975,n−1·√(n+1)/n·sd,onde t 0,975, n-1 {\ displayStyle t_ {0.975, n-1}} é o quantil 97,5% da distribuição t de um aluno com n-1 graus de liberdade.
Quando o tamanho da amostra é grande (n≥30) t 0,975, n-1 ≃ 2. {\ displayStyle t_ {0,975, n-1} \ simeq 2.}
Esse método é frequentemente aceitavelmente preciso se o desvio padrão, em comparação com a média, não for muito grande. Um método mais preciso é executar os cálculos sobre valores logaritmizados, conforme descrito em seção separada posteriormente.
O exemplo a seguir deste método (não logaritmizado) é baseado nos valores da glicose em jejum, retirada de um grupo de referência de 12 indivíduos:
Fasting plasma glucose (FPG) in mmol/LDeviation from mean mSquared deviationfrom mean mSubject 15.50.170.029Subject 25.2-0.130.017Subject 35.2-0.130.017Subject 45.80.470.221Subject 55.60.270.073Subject 64.6-0.730.533Subject 75.60.270.073Subject 85.90.570.325Subject 94.7-0.630.397Subject 105-0.330.109Subject 115.70.370.137Subject 125.2-0.130.017Mean = 5.33 (m) n=12Mean = 0.00Sum/(n−1) = 1.95/11 =0.18 0.18 = 0.42 {\displaystyle {\sqrt {0.18}}=0.42} = standard deviation (s.d.)
= standard deviation (s.d.)Como pode ser dado a partir de, por exemplo, uma tabela de valores selecionados da distribuição T de Student, o percentil de 97,5% com (12-1) graus de liberdade corresponde a t 0,975, 11 = 2,20 {\ displayStyle t_ {0,975,11} = 2.20}
Posteriormente, os limites inferiores e superiores da faixa de referência padrão são calculados como:
L o w e r l i m i t = m − t 0.975 , 11 × n + 1 n × s . d . = 5.33 − 2.20 × 13 12 × 0.42 = 4.4 {\displaystyle Lower~limit=m-t_{0.975,11}\times {\sqrt {\frac {n+1}{n}}}\times s.d.=5.33-2.20\times {\sqrt {\frac {13}{12}}}\times 0.42=4.4} U p p e r l i m i t = m + t 0.975 , 11 × n + 1 n × s . d . = 5.33 + 2.20 × 13 12 × 0.42 = 6.3. {\displaystyle Upper~limit=m+t_{0.975,11}\times {\sqrt {\frac {n+1}{n}}}\times s.d.=5.33+2.20\times {\sqrt {\frac {13}{12}}}\times 0.42=6.3.}
U p p e r l i m i t = m + t 0.975 , 11 × n + 1 n × s . d . = 5.33 + 2.20 × 13 12 × 0.42 = 6.3. {\displaystyle Upper~limit=m+t_{0.975,11}\times {\sqrt {\frac {n+1}{n}}}\times s.d.=5.33+2.20\times {\sqrt {\frac {13}{12}}}\times 0.42=6.3.} 
Assim, o intervalo de referência padrão para este exemplo é estimado em 4,4 a 6,3 mmol/L.
Confidence interval of limitO intervalo de confiança de 90% de um limite de faixa de referência padrão, estimado, assumindo que uma distribuição normal pode ser calculada por:
Lower limit of the confidence interval = percentile limit - 2.81 × SD⁄√nUpper limit of the confidence interval = percentile limit + 2.81 × SD⁄√n,onde SD é o desvio padrão e n é o número de amostras.
Tomando o exemplo da seção anterior, o número de amostras é 12 e o desvio padrão é de 0,42 mmol/L, resultando em:
Lower limit of the confidence interval of the lower limit of the standard reference range = 4.4 - 2.81 × 0.42⁄√12 ≈ 4.1Upper limit of the confidence interval of the lower limit of the standard reference range = 4.4 + 2.81 × 0.42⁄√12 ≈ 4.7Assim, o limite inferior da faixa de referência pode ser escrito como 4,4 (IC 90% 4,1-4,7) mmol/L.
Da mesma forma, com cálculos semelhantes, o limite superior da faixa de referência pode ser escrito como 6,3 (IC 90% 6,0–6,6) mmol/L.
Esses intervalos de confiança refletem erros aleatórios, mas não compensam o erro sistemático, que neste caso podem surgir, por exemplo, o grupo de referência que não tem jejuado por tempo suficiente antes da amostragem de sangue.
Como comparação, estima -se que as faixas de referência reais usadas clinicamente para a glicose plasmática em jejum tenham um limite inferior de aproximadamente 3,8 a 4,0 e um limite superior de aproximadamente 6,0 a 6,1.
Log-normal distribution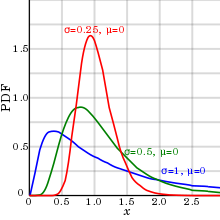
Na realidade, os parâmetros biológicos tendem a ter uma distribuição log-normal, em vez da distribuição normal aritmética (que geralmente é referida como distribuição normal sem nenhuma especificação adicional).
Uma explicação para essa distribuição log-normal para parâmetros biológicos é: o evento em que uma amostra tem metade do valor da média ou mediana tende a ter quase igual probabilidade a ocorrer como o evento em que uma amostra tem o dobro do valor da média ou mediana . Além disso, apenas uma distribuição log-normal pode compensar a incapacidade de quase todos os parâmetros biológicos de números negativos (pelo menos quando medidos em escalas absolutas), com a conseqüência de que não há limite definido para o tamanho dos valores discrepantes (valores extremos ) no lado alto, mas, por outro lado, eles nunca podem ser inferiores a zero, resultando em uma assimetria positiva.
Como mostrado no diagrama à direita, esse fenômeno tem efeito relativamente pequeno se o desvio padrão (em comparação com a média) é relativamente pequeno, pois faz com que a distribuição log-normal pareça semelhante a uma distribuição normal aritmética. Assim, a distribuição normal aritmética pode ser mais apropriada para usar com pequenos desvios padrão para conveniência e a distribuição log-normal com grandes desvios padrão.
Em uma distribuição log-normal, os desvios padrão geométricos e a geométrica significam mais com mais precisão o intervalo de previsão de 95% do que suas contrapartes aritméticas.
NecessityA necessidade de estabelecer um intervalo de referência por distribuição log-normal, em vez da distribuição normal aritmética, pode ser considerada como dependendo de quanta diferença faria para não fazê-lo, o que pode ser descrito como a proporção:
Difference ratio = | Limitlog-normal - Limitnormal |/ Limitlog-normalOnde:
Limitlog-normal is the (lower or upper) limit as estimated by assuming log-normal distributionLimitnormal is the (lower or upper) limit as estimated by assuming arithmetically normal distribution.
Essa diferença pode ser colocada apenas em relação ao coeficiente de variação, como no diagrama à direita, onde:
Coefficient of variation = s.d./mOnde:
s.d. is the arithmetic standard deviationm is the arithmetic meanNa prática, pode ser considerado necessário usar os métodos de estabelecimento de uma distribuição log-normal se a taxa de diferença se tornar mais de 0,1, o que significa que um limite (inferior ou superior) estimado a partir de uma distribuição aritmeticamente normal assumida seria superior a 10 % diferente do limite correspondente, estimado a partir de uma distribuição log-normal (mais precisa). Como visto no diagrama, é atingida uma taxa de diferença de 0,1 para o limite inferior em um coeficiente de variação de 0,213 (ou 21,3%) e para o limite superior em um coeficiente de variação em 0,413 (41,3%). O limite inferior é mais afetado pelo aumento do coeficiente de variação, e seu coeficiente "crítico" de variação de 0,213 corresponde a uma razão de (limite superior)/(limite inferior) de 2,43, portanto, como regra geral, se o limite superior do limite é mais de 2,4 vezes o limite inferior quando estimado assumindo a distribuição aritmeticamente normal, deve-se considerar os cálculos novamente por distribuição log-normal.
Tomando o exemplo da seção anterior, o desvio padrão aritmético (S.D.) é estimado em 0,42 e a média aritmética (M) é estimada em 5,33. Assim, o coeficiente de variação é 0,079. Isso é menor que 0,213 e 0,413 e, portanto, o limite inferior e superior da glicose no sangue em jejum pode provavelmente ser estimado assumindo a distribuição aritmeticamente normal. Mais especificamente, o coeficiente de variação de 0,079 corresponde a uma taxa de diferença de 0,01 (1%) para o limite inferior e 0,007 (0,7%) para o limite superior.
From logarithmized sample valuesUm método para estimar o intervalo de referência para um parâmetro com distribuição log-normal é logaritmizar todas as medidas com uma base arbitrária (por exemplo e), derivar a média e o desvio padrão desses logaritmos, determinar os logaritmos localizados (para 95% intervalo de previsão) 1,96 desvios padrão abaixo e acima dessa média e, posteriormente, exponenciando usando esses dois logaritmos como expoentes e usando a mesma base usada no logaritmo, com os dois valores resultantes sendo o limite inferior e superior do intervalo de previsão de 95%.
O exemplo a seguir deste método é baseado nos mesmos valores de glicose em jejum, usada na seção anterior, usando e como uma base:
Fasting plasma glucose (FPG) in mmol/Lloge(FPG)loge(FPG) deviation from mean μlogSquared deviationfrom meanSubject 15.51.700.0290.000841Subject 25.21.650.0210.000441Subject 35.21.650.0210.000441Subject 45.81.760.0890.007921Subject 55.61.720.0490.002401Subject 64.61.530.1410.019881Subject 75.61.720.0490.002401Subject 85.91.770.0990.009801Subject 94.71.550.1210.014641Subject 105.01.610.0610.003721Subject 115.71.740.0690.004761Subject 125.21.650.0210.000441Mean: 5.33 (m)Mean: 1.67 (μlog)Sum/(n-1) : 0.068/11 = 0.0062 0.0062 = 0.079 {\displaystyle {\sqrt {0.0062}}=0.079} = standard deviation of loge(FPG) (σlog)
= standard deviation of loge(FPG) (σlog)Posteriormente, o limite inferior ainda logaritmizado da faixa de referência é calculado como:
ln ( lower limit ) = μ log − t 0.975 , n − 1 × n + 1 n × σ log = 1.67 − 2.20 × 13 12 × 0.079 = 1.49 , {\displaystyle {\begin{aligned}\ln({\text{lower limit}})&=\mu _{\log }-t_{0.975,n-1}\times {\sqrt {\frac {n+1}{n}}}\times \sigma _{\log }\\&=1.67-2.20\times {\sqrt {\frac {13}{12}}}\times 0.079=1.49,\end{aligned}}}
e o limite superior do intervalo de referência como:
ln ( upper limit ) = μ log + t 0.975 , n − 1 × n + 1 n × σ log = 1.67 + 2.20 × 13 12 × 0.079 = 1.85 {\displaystyle {\begin{aligned}\ln({\text{upper limit}})&=\mu _{\log }+t_{0.975,n-1}\times {\sqrt {\frac {n+1}{n}}}\times \sigma _{\log }\\&=1.67+2.20\times {\sqrt {\frac {13}{12}}}\times 0.079=1.85\end{aligned}}}
A conversão de volta aos valores não logaritmizados é subsequentemente realizada como:
Lower limit = e ln ( lower limit ) = e 1.49 = 4.4 {\displaystyle {\text{Lower limit}}=e^{\ln({\text{lower limit}})}=e^{1.49}=4.4} Upper limit = e ln ( upper limit ) = e 1.85 = 6.4 {\displaystyle {\text{Upper limit}}=e^{\ln({\text{upper limit}})}=e^{1.85}=6.4}
Upper limit = e ln ( upper limit ) = e 1.85 = 6.4 {\displaystyle {\text{Upper limit}}=e^{\ln({\text{upper limit}})}=e^{1.85}=6.4} 
Assim, o intervalo de referência padrão para este exemplo é estimado em 4,4 a 6.4.
From arithmetic mean and varianceUm método alternativo para estabelecer um intervalo de referência com a suposição de distribuição log-normal é usar a média aritmética e o valor aritmético do desvio padrão. Isso é um pouco mais tedioso de executar, mas pode ser útil, por exemplo, nos casos em que um estudo que estabelece um intervalo de referência apresenta apenas a média aritmética e o desvio padrão, deixando de fora os dados de origem. Se a suposição original de distribuição aritmeticamente normal for mostrada menos apropriada que a normais log, então, usando a média aritmética e o desvio padrão, podem ser os únicos parâmetros disponíveis para corrigir o intervalo de referência.
Ao assumir que o valor esperado pode representar a média aritmética neste caso, os parâmetros μlog e σlog podem ser estimados a partir da média aritmética (M) e desvio padrão (S.D.) como:
μ log = ln ( m ) − 1 2 ln ( 1 + ( s.d. m ) 2 ) {\displaystyle \mu _{\log }=\ln(m)-{\frac {1}{2}}\ln \!\left(1+\!\left({\frac {\text{s.d.}}{m}}\right)^{2}\right)} σ log = ln ( 1 + ( s.d. m ) 2 ) {\displaystyle \sigma _{\log }={\sqrt {\ln \!\left(1+\!\left({\frac {\text{s.d.}}{m}}\right)^{2}\right)}}}
σ log = ln ( 1 + ( s.d. m ) 2 ) {\displaystyle \sigma _{\log }={\sqrt {\ln \!\left(1+\!\left({\frac {\text{s.d.}}{m}}\right)^{2}\right)}}} 
Após o grupo de referência examinado da seção anterior:
μ log = ln ( 5.33 ) − 1 2 ln ( 1 + ( 0.42 5.33 ) 2 ) = 1.67 {\displaystyle \mu _{\log }=\ln(5.33)-{\frac {1}{2}}\ln \!\left(1+\!\left({\frac {0.42}{5.33}}\right)^{2}\right)=1.67} σ log = ln ( 1 + ( 0.42 5.33 ) 2 ) = 0.079 {\displaystyle \sigma _{\log }={\sqrt {\ln \!\left(1+\!\left({\frac {0.42}{5.33}}\right)^{2}\right)}}=0.079}
σ log = ln ( 1 + ( 0.42 5.33 ) 2 ) = 0.079 {\displaystyle \sigma _{\log }={\sqrt {\ln \!\left(1+\!\left({\frac {0.42}{5.33}}\right)^{2}\right)}}=0.079} 
Posteriormente, os logaritmizados e posteriormente não logaritmizados, o limite inferior e superior são calculados como os valores da amostra logaritmizados.
Directly from percentages of interestOs intervalos de referência também podem ser estabelecidos diretamente do percentil 2.5 e 97.5 das medições no grupo de referência. Por exemplo, se o grupo de referência consistir em 200 pessoas e a contagem da medição com menor valor para o mais alto, o limite inferior da faixa de referência corresponderia à 5ª medição e o limite superior corresponderia à 195ª medição.
Esse método pode ser usado mesmo quando os valores de medição não parecem estar em conformidade com qualquer forma de distribuição normal ou outra função.
No entanto, o intervalo de referência limita, conforme estimado dessa maneira, tem maior variação e, portanto, menos confiabilidade, do que aqueles estimados por uma distribuição aritmética ou log-normal (quando é aplicável), porque os últimos adquirem poder estatístico das medições do Grupo de referência inteira, em vez de apenas as medições nos percentis 2,5 e 97.5. Ainda assim, essa variação diminui com o tamanho crescente do grupo de referência e, portanto, esse método pode ser ideal quando um grande grupo de referência pode ser facilmente coletado e o modo de distribuição das medições é incerto.
Bimodal distribution
No caso de uma distribuição bimodal (vista à direita), é útil descobrir por que esse é o caso. Duas faixas de referência podem ser estabelecidas para os dois grupos diferentes de pessoas, possibilitando assumir uma distribuição normal para cada grupo. Esse padrão bimodal é comumente visto em testes que diferem entre homens e mulheres, como o antígeno específico da próstata.
Interpretação de intervalos padrão em exames médicos
No caso de exames médicos cujos resultados são de valores contínuos, faixas de referência podem ser usadas na interpretação de um resultado de teste individual. Isso é usado principalmente para testes de diagnóstico e triagem, enquanto os testes de monitoramento podem ser interpretados de maneira ideal a partir de testes anteriores do mesmo indivíduo.
Probability of random variabilityAs faixas de referência ajudam na avaliação de se o desvio de um resultado do teste da média é resultado de variabilidade aleatória ou resultado de uma doença ou condição subjacente. Se o grupo de referência usado para estabelecer o intervalo de referência pode ser considerado representativo da pessoa em um estado saudável, um resultado de teste desse indivíduo que acaba sendo menor ou superior ao intervalo de referência pode ser interpretado como lá é menor que 2,5% de probabilidade de que isso tenha ocorrido pela variabilidade aleatória na ausência de doença ou outra condição, que, por sua vez, é fortemente indicativa para considerar uma doença ou condição subjacente como causa.
Essa consideração adicional pode ser realizada, por exemplo, por um procedimento de diagnóstico diferencial baseado em epidemiologia, onde são listadas possíveis condições do candidato que podem explicar a descoberta, seguida de cálculos de quão provável eles devem ter ocorrido em primeiro lugar, por sua vez, seguidos por uma comparação com a probabilidade de que o resultado tenha ocorrido pela variabilidade aleatória.
Se o estabelecimento do intervalo de referência pudesse ter sido feito assumindo uma distribuição normal, a probabilidade de que o resultado seja um efeito da variabilidade aleatória possa ser mais especificada da seguinte forma:
O desvio padrão, se não for dado, pode ser inversamente calculado pelo fato de que o valor absoluto da diferença entre a média e o limite superior ou inferior da faixa de referência é de aproximadamente 2 desvios padrão (mais precisamente 1,96) e, portanto, :
Standard deviation (s.d.) ≈ | (Mean) - (Upper limit) |/2.A pontuação padrão para o teste do indivíduo pode ser calculada posteriormente como:
Standard score (z) = | (Mean) - (individual measurement) |/s.d..A probabilidade de que um valor seja de uma certa distância da média possa ser posteriormente calculada a partir da relação entre os intervalos de pontuação padrão e previsão. Por exemplo, uma pontuação padrão de 2,58 corresponde a um intervalo de previsão de 99%, correspondendo a uma probabilidade de 0,5%, o resultado está pelo menos tão longe da média na ausência de doença.
ExampleDigamos, por exemplo, que um indivíduo faça um teste que mede o cálcio ionizado no sangue, resultando em um valor de 1,30 mmol/L, e um grupo de referência que representa adequadamente o indivíduo estabeleceu um intervalo de referência de 1,05 a 1,25 mmol /EU. O valor do indivíduo é maior que o limite superior da faixa de referência e, portanto, tem menos de 2,5% de probabilidade de ser resultado da variabilidade aleatória, constituindo uma forte indicação para fazer um diagnóstico diferencial de possíveis condições causais.
Nesse caso, um procedimento de diagnóstico diferencial baseado em epidemiologia é usado e seu primeiro passo é encontrar condições candidatas que possam explicar a descoberta.
A hipercalcemia (geralmente definida como um nível de cálcio acima da faixa de referência) é causada principalmente pelo hiperparatireoidismo primário ou malignidade e, portanto, é razoável incluí -las no diagnóstico diferencial.
Usando, por exemplo, a epidemiologia e os fatores de risco do indivíduo, digamos que a probabilidade de a hipercalcemia ter sido causada pelo hiperparatireoidismo primário em primeiro lugar é estimado em 0,00125 (ou 0,125%), a probabilidade equivalente ao câncer é 0,0002 e 0,0005 Para outras condições. Com uma probabilidade dada menos de 0,025 de nenhuma doença, isso corresponde a uma probabilidade de que a hipercalcemia tenha ocorrido no primeiro local de até 0,02695. No entanto, a hipercalcemia ocorreu com uma probabilidade de 100%, resultantes de probabilidades ajustadas de pelo menos 4,6% de que o hiperparatireoidismo primário causou a hipercalcemia, pelo menos 0,7% para câncer, pelo menos 1,9% para outras condições e até 92,8% para isso Não há doença e a hipercalcemia é causada por variabilidade aleatória.
Nesse caso, o processamento adicional dos benefícios da especificação da probabilidade de variabilidade aleatória:
Presume -se que o valor se conforme aceita a uma distribuição normal; portanto, a média pode ser assumida como 1,15 no grupo de referência. O desvio padrão, se não for dado, pode ser inversamente calculado sabendo que o valor absoluto da diferença entre a média e, por exemplo, o limite superior do intervalo de referência, é de aproximadamente 2 desvios padrão (mais precisamente 1,96) e portanto:
Standard deviation (s.d.) ≈ | (Mean) - (Upper limit) |/2 = | 1.15 - 1.25 |/2 = 0.1/2 = 0.05.A pontuação padrão para o teste do indivíduo é posteriormente calculada como:
Standard score (z) = | (Mean) - (individual measurement) |/s.d. = | 1.15 - 1.30 |/0.05 = 0.15/0.05 = 3.A probabilidade de que um valor seja de valor tão maior que a média como ter uma pontuação padrão de 3 corresponde a uma probabilidade de aproximadamente 0,14% (dada por (100% - 99,7%)/2, com 99,7% aqui sendo dado do dado a partir do 68–95–99.7 Regra).
Usando as mesmas probabilidades que a hipercalcemia teria ocorrido em primeiro lugar pelas outras condições do candidato, a probabilidade de a hipercalcemia ter ocorrido em primeiro lugar é 0,00335 e, dado o fato de que a hipercalcemia ocorreu fornece probabilidades ajustadas de 37,3%, 6.0 %, 14,9%e 41,8%, respectivamente, para hiperparatireoidismo primário, câncer, outras condições e nenhuma doença.
Faixa de saúde ideal
A faixa ideal (de saúde) ou alvo terapêutico (não deve ser confundido com o alvo biológico) é um intervalo de referência ou limite baseado em concentrações ou níveis associados a saúde ideal ou risco mínimo de complicações e doenças relacionadas, em vez da faixa padrão com base na distribuição normal na população.
Pode ser mais apropriado usar, por exemplo O folato, uma vez que aproximadamente 90 % dos norte -americanos podem realmente sofrer mais ou menos com a deficiência de folato, mas apenas os 2,5 % que têm os níveis mais baixos ficarão abaixo do intervalo de referência padrão. Nesse caso, os intervalos reais de folato para a saúde ideal são substancialmente mais altos que os intervalos de referência padrão. A vitamina D tem uma tendência semelhante. Por outro lado, por p. O ácido úrico, com um nível que não excede o intervalo de referência padrão ainda não exclui o risco de obter pedras de gota ou rim. Além disso, para a maioria das toxinas, o intervalo de referência padrão é geralmente menor que o nível de efeito tóxico.
Um problema com a faixa ideal de saúde é a falta de um método padrão de estimativa dos intervalos. Os limites podem ser definidos como aqueles em que os riscos à saúde excedem um certo limite, mas com vários perfis de risco entre diferentes medições (como folato e vitamina D) e até aspectos de risco diferentes para uma e a mesma medição (como deficiência e deficiência e Toxicidade da vitamina A) É difícil padronizar. Posteriormente, as faixas de saúde ideais, quando dadas por várias fontes, têm uma variabilidade adicional causada por várias definições do parâmetro. Além disso, como nos intervalos de referência padrão, deve haver faixas específicas para diferentes determinantes que afetam os valores, como sexo, idade etc. Idealmente, deve haver uma estimativa do que é o valor ideal para cada indivíduo, ao tomar todos os significativos Fatores desse indivíduo em consideração - uma tarefa que pode ser difícil de alcançar por estudos, mas a longa experiência clínica por um médico pode tornar esse método preferível ao uso de faixas de referência.
Valores de corte unilateral
Em muitos casos, apenas um lado da faixa é geralmente de interesse, como marcadores de patologia, incluindo o antígeno do câncer 19-9, onde geralmente é sem nenhum significado clínico ter um valor abaixo do habitual na população. Portanto, esses alvos são frequentemente fornecidos com apenas um limite do intervalo de referência fornecido e, estritamente, esses valores são valores bastante cortados ou valores limiares.
Eles podem representar faixas padrão e faixas de saúde ideais. Além disso, eles podem representar um valor apropriado para distinguir uma pessoa saudável de uma doença específica, embora isso dê variabilidade adicional por diferentes doenças que estão sendo distinguidas. Por exemplo, para o NT-proBNP, um valor de corte mais baixo é usado na distinção de bebês saudáveis daqueles com doença cardíaca acianenótica, em comparação com o valor de corte usado na distinção de bebês saudáveis daqueles com anemia não esferocítica congênita.
Desvantagens gerais
Para faixas de saúde padrão e ideais e pontos de corte, as fontes de imprecisão e imprecisão incluem:
Instruments and lab techniques used, or how the measurements are interpreted by observers. These may apply both to the instruments etc. used to establish the reference ranges and the instruments, etc. used to acquire the value for the individual to whom these ranges is applied. To compensate, individual laboratories should have their own lab ranges to account for the instruments used in the laboratory.Determinants such as age, diet, etc. that are not compensated for. Optimally, there should be reference ranges from a reference group that is as similar as possible to each individual they are applied to, but it's practically impossible to compensate for every single determinant, often not even when the reference ranges are established from multiple measurements of the same individual they are applied to, because of test-retest variability.Além disso, os intervalos de referência tendem a dar a impressão de limiares definidos que claramente separam valores "bons" ou "ruins", enquanto na realidade geralmente existem riscos continuamente aumentando com maior distância dos valores usuais ou ótimos.
Com isso e fatores não compensados em mente, o método ideal de interpretação de um resultado de teste prefere consistir em uma comparação do que seria esperado ou ideal no indivíduo ao levar em conta todos os fatores e condições desse indivíduo, em vez de classificar estritamente os valores como "bom" ou "ruim", usando varia de outras pessoas.
Em um artigo recente, Rappoport et al. descreveu uma nova maneira de redefinir a faixa de referência de um sistema eletrônico de registros de saúde. Nesse sistema, uma resolução populacional mais alta pode ser alcançada (por exemplo, idade, sexo, raça e etnia).