






Produção de fala
Content
Três estágios
A produção da linguagem falada envolve três níveis principais de processamento: conceitualização, formulação e articulação.
O primeiro são os processos de conceituação ou preparação conceitual, na qual a intenção de criar a fala vincula um conceito desejado às palavras faladas a serem expressas. Aqui, são formuladas mensagens preversais que especificam os conceitos a serem expressos.
O segundo estágio é a formulação na qual a forma linguística necessária para a expressão da mensagem desejada é criada. A formulação inclui codificação gramatical, codificação morfonológica e codificação fonética. A codificação gramatical é o processo de seleção da palavra sintática ou lema apropriada. O lema selecionado ativa o quadro sintático apropriado para a mensagem conceituada. A codificação morfonológica é o processo de dividir palavras em sílabas a serem produzidas na fala aberta. A silabificação depende das palavras anteriores e procedidas, por exemplo: i-com-pre-hend vs.-com-pre-hen-dit. A parte final do estágio de formulação é a codificação fonética. Isso envolve a ativação de gestos articulatórios dependentes das sílabas selecionadas no processo morfonológico, criando uma pontuação articulatória à medida que a expressão é reunida e a ordem dos movimentos do aparelho vocal é concluída.
A terceira etapa da produção da fala é a articulação, que é a execução da pontuação articulatória pelos pulmões, glote, laringe, língua, lábios, mandíbula e outras partes do aparato vocal, resultando em fala.
Neurociência
O controle motor para a produção de fala em pessoas destro depende principalmente de áreas no hemisfério cerebral esquerdo. Essas áreas incluem a área motora suplementar bilateral, o giro frontal inferior posterior esquerdo, a ínsula esquerda, o córtex motor primário esquerdo e o córtex temporal. Também existem áreas subcorticais envolvidas, como os gânglios da base e o cerebelo. O cerebelo ajuda o sequenciamento de sílabas de fala em palavras rápidas, lisas e ritmicamente organizadas e enunciados mais longos.
Distúrbios
A produção de fala pode ser afetada por vários distúrbios:
História da pesquisa de produção de fala

Até o final da década de 1960, a pesquisa sobre discurso estava focada na compreensão. À medida que os pesquisadores coletaram maiores volumes de dados de erro de fala, eles começaram a investigar os processos psicológicos responsáveis pela produção de sons da fala e a contemplar possíveis processos para a fala fluente. As descobertas da pesquisa de erros de fala logo foram incorporadas aos modelos de produção de fala. Evidências de dados de erro de fala suportam as seguintes conclusões sobre a produção de fala.
Algumas dessas idéias incluem:
Speech is planned in advance.The lexicon is organized both semantically and phonologically. That is by meaning, and by the sound of the words.Morphologically complex words are assembled. Words that we produce that contain morphemes are put together during the speech production process. Morphemes are the smallest units of language that contain meaning. For example, "ed" on a past tense word.Affixes and functors behave differently from context words in slips of the tongue. This means the rules about the ways in which a word can be used are likely stored with them, which means generally when speech errors are made, the mistake words maintain their functions and make grammatical sense.Speech errors reflect rule knowledge. Even in our mistakes, speech is not nonsensical. The words and sentences that are produced in speech errors are typically grammatical, and do not violate the rules of the language being spoken.Aspectos dos modelos de produção de fala
Os modelos de produção de fala devem conter elementos específicos para serem viáveis. Isso inclui os elementos dos quais o discurso é composto, listado abaixo. Os modelos aceitos de produção de fala discutidos em mais detalhes abaixo incorporam esses estágios explícitos ou implicitamente, e os que agora estão desatualizados ou disputados foram criticados por ignorar um ou mais dos estágios a seguir.
Os atributos dos modelos de fala aceitos são:
a) Um estágio conceitual em que o falante identifica abstrivelmente o que deseja expressar.
b) Um estágio sintático onde um quadro é escolhido em que as palavras serão colocadas, esse quadro geralmente é a estrutura da frase.
c) Um estágio lexical em que uma pesquisa por uma palavra ocorre com base no significado. Depois que a palavra é selecionada e recuperada, as informações sobre ela ficam disponíveis para o orador envolvendo fonologia e morfologia.
d) um estágio fonológico em que a informação abstrata é convertida em uma forma de fala.
e) Um estágio fonético onde as instruções são preparadas para serem enviadas aos músculos da articulação.
Além disso, os modelos devem permitir mecanismos de planejamento a termo, um buffer e um mecanismo de monitoramento.
A seguir, alguns dos modelos influentes de produção de fala que representam ou incorporam os estágios mencionados anteriormente e incluem informações descobertas como resultado de estudos de erro de fala e outros dados de disfluência, como pesquisas de ponta da língua.
Modelo
O modelo do gerador de enunciado (1971)
O modelo do gerador de enunciado foi proposto por Fromkin (1971). É composto por seis etapas e foi uma tentativa de explicar as descobertas anteriores da pesquisa de erros de fala. Os estágios do modelo do gerador de enunciado foram baseados em possíveis alterações nas representações de uma expressão específica. A primeira etapa é onde uma pessoa gera o significado que deseja transmitir. O segundo estágio envolve a mensagem sendo traduzida em uma estrutura sintática. Aqui, a mensagem recebe um esboço. O terceiro estágio proposto por Fromkin é onde/quando a mensagem ganha tensões e entonações diferentes com base no significado. A quarta etapa de Fromkin sugerida está preocupada com a seleção de palavras do léxico. Depois que as palavras foram selecionadas no estágio 4, a mensagem sofre especificação fonológica. O quinto estágio aplica regras de pronúncia e produz sílabas a serem produzidas. A sexta e última etapa do modelo gerador de enunciado de Fromkin é a coordenação dos comandos motores necessários para a fala. Aqui, as características fonéticas da mensagem são enviadas aos músculos relevantes do trato vocal para que a mensagem pretendida possa ser produzida. Apesar da ingenuidade do modelo de Fromkin, os pesquisadores criticaram essa interpretação da produção da fala. Embora o modelo do gerador de enunciado seja responsável por muitas nuances e dados encontrados por estudos de erro de fala, os pesquisadores decidiram que ainda tinha espaço para melhorar.
The Garrett Model (1975)
Uma tentativa mais recente (do que Fromkin) de explicar a produção de fala foi publicada por Garrett em 1975. Garrett também criou esse modelo compilando dados de erro de fala. Existem muitas sobreposições entre esse modelo e o modelo Fromkin, do qual se baseava, mas ele adicionou algumas coisas ao modelo Fromkin que preencheu algumas das lacunas apontadas por outros pesquisadores. Os modelos de Garrett Fromkin distinguem entre três níveis - um nível conceitual e nível de sentença e um nível motor. Esses três níveis são comuns à compreensão contemporânea da produção da fala.

Modelo de Dell (1994)
Em 1994, a Dell propôs um modelo da rede lexical que se tornou fundamental na compreensão da maneira como a fala é produzida. Esse modelo da rede lexical tenta representar simbolicamente o léxico e, por sua vez, explica como as pessoas escolhem as palavras que desejam produzir e como essas palavras devem ser organizadas em fala. O modelo de Dell era composto por três estágios, semântica, palavras e fonemas. As palavras no estágio mais alto do modelo representam a categoria semântica. (Na imagem, as palavras que representam categoria semântica são inverno, calçados, pés e neve representam as categorias semânticas de bota e skate.) O segundo nível representa as palavras que se referem à categoria semântica (na imagem, bota e skate) . E o terceiro nível representa os fonemas (informações silábicas, incluindo início, vogais e codas).
Modelo Levelt (1999)
O Levelt refinou ainda mais a rede lexical proposta pela Dell. Através do uso de dados de erro de fala, o Levelt recriou os três níveis no modelo da Dell. O estrato conceitual, o nível superior e mais abstrato, contém informações que uma pessoa tem sobre idéias de conceitos específicos. O estrato conceitual também contém idéias sobre como os conceitos se relacionam. É aqui que a seleção de palavras ocorreria, uma pessoa escolheria quais palavras deseja expressar. O próximo, ou nível médio, o lema-estrato, contém informações sobre as funções sintáticas de palavras individuais, incluindo tempo e função. Esse nível funciona para manter a sintaxe e colocar as palavras corretamente na estrutura de frases que fazem sentido para o falante. O nível mais baixo e final é o estrato do formulário que, da mesma forma que o modelo Dell, contém informações silábicas. A partir daqui, as informações armazenadas no nível do estrato do formulário são enviadas ao córtex motor, onde o aparelho vocal é coordenado para produzir fisicamente sons de fala.
Locais de articulação
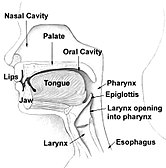
A estrutura física do nariz humano, garganta e cordas vocais permite as produções de muitos sons únicos, essas áreas podem ser divididas em locais de articulação. Sons diferentes são produzidos em diferentes áreas e com diferentes músculos e técnicas de respiração. Nossa capacidade de utilizar essas habilidades para criar os vários sons necessários para se comunicar efetivamente é essencial para a nossa produção de fala. A fala é uma atividade psicomotora. A fala entre duas pessoas é uma conversa - elas podem ser casuais, formais, factuais ou transacionais, e a estrutura da linguagem/ gênero narrativo empregado difere dependendo do contexto. O afeto é um fator significativo que controla a fala, manifestações que interrompem a memória no uso da linguagem devido a afetar incluem sentimentos de tensão, estados de apreensão e sinais físicos como náusea. Manifestações no nível da linguagem que afetam trazem que podem ser observadas com as hesitações, repetições, falsas partidas, incompleção, misturas sintáticas, etc. Dificuldades de maneira de articulação podem contribuir para dificuldades e impedimentos da fala. Sugere -se que os bebês sejam capazes de criar todo o espectro de possíveis sons de vogal e consoante. A IPA criou um sistema para entender e categorizar todos os sons de fala possíveis, que incluem informações sobre a maneira como o som é produzido e onde os sons são produzidos. Isso é extremamente útil no entendimento da produção da fala, porque a fala pode ser transcrita com base em sons, e não em ortografia, o que pode ser enganoso, dependendo do idioma que está sendo falado. As taxas de fala média estão na faixa de 120 a 150 palavras por minuto (WPM), e o mesmo são as diretrizes recomendadas para gravar audiolivros. À medida que as pessoas se acostumam a um idioma específico, eles são propensos a perder não apenas a capacidade de produzir certos sons da fala, mas também de distinguir entre esses sons.
Articulação
A articulação, frequentemente associada à produção da fala, é como as pessoas produzem fisicamente sons de fala. Para as pessoas que falam fluentemente, a articulação é automática e permite que 15 sons de fala sejam produzidos por segundo.
Uma articulação eficaz da fala inclui os seguintes elementos - fluência, complexidade, precisão e compreensibilidade.
Fluency: Is the ability to communicate an intended message, or to affect the listener in the way that is intended by the speaker. While accurate use of language is a component in this ability, over-attention to accuracy may actually inhibit the development of fluency. Fluency involves constructing coherent utterances and stretches of speech, to respond and to speak without undue hesitation (limited use of fillers such as uh, er, eh, like, you know). It also involves the ability to use strategies such as simplification and gestures to aid communication. Fluency involves use of relevant information, appropriate vocabulary and syntax.Complexity: Speech where the message is communicated precisely. Ability to adjust the message or negotiate the control of conversation according to the responses of the listener, and use subordination and clausal forms appropriate per the roles and relationship between the speakers. It includes the use of sociolinguistic knowledge – the skills required to communicate effectively across cultures; the norms, the knowledge of what is appropriate to say in what situations and to whom.Accuracy: This refers to the use of proper and advanced grammar; subject-verb agreement; word order; and word form (excited/exciting), as well as appropriate word choice in spoken language. It is also the ability to self-correct during discourse, to clarify or modify spoken language for grammatical accuracy.Comprehensibility: This is the ability to be understood by others, it is related with the sound of the language. There are three components that influence one’s comprehensibility and they are: Pronunciation – saying the sounds of words correctly; Intonation – applying proper stress on words and syllables, using rising and falling pitch to indicate questions or statements, using voice to indicate emotion or emphasis, speaking with an appropriate rhythm; and Enunciation – speaking clearly at an appropriate pace, with effective articulation of words and phrases and appropriate volume.Desenvolvimento
Antes mesmo de produzir um som, os bebês imitam expressões e movimentos faciais. Cerca de 7 meses de idade, os bebês começam a experimentar sons comunicativos, tentando coordenar a produção de som com a abertura e o fechamento da boca.
Até o primeiro ano de vida que os bebês não podem produzir palavras coerentes, em vez disso, produzem um som balbuciante recorrente. O balbucio permite que o bebê experimente sons articulando sem ter que atender ao significado. Essa balbuciação repetida inicia a produção inicial da fala. Babilizar trabalha com permanência e compreensão do objetivo para apoiar as redes de nossos primeiros itens ou palavras lexicais. O crescimento do vocabulário da criança aumenta substancialmente quando é capaz de entender que existem objetos mesmo quando não estão presentes.
A primeira etapa do discurso significativo não ocorre até a idade de um. Este estágio é a fase holofrástica. O estágio holístico refere -se quando o discurso infantil consiste em uma palavra de cada vez (ou seja, papai).
O próximo estágio é a fase telegráfica. Nesse estágio, os bebês podem formar frases curtas (ou seja, papai sentar ou beber mamãe). Isso geralmente ocorre entre idades de um e meio e dois anos e meio de idade. Este estágio é particularmente digno de nota devido ao crescimento explosivo de seu léxico. Durante esse estágio, os bebês devem selecionar e combinar representações armazenadas de palavras com a palavra de destino perceptiva específica para transmitir significado ou conceitos. Com vocabulário suficiente, os bebês começam a extrair padrões de som e aprendem a dividir as palavras em segmentos fonológicos, aumentando ainda mais o número de palavras que podem aprender. Neste ponto do desenvolvimento de fala de uma criança, seu léxico consiste em 200 palavras ou mais e elas são capazes de entender ainda mais do que podem falar.
Quando eles atingem dois anos e meio, sua produção de fala se torna cada vez mais complexa, principalmente em sua estrutura semântica. Com uma rede semântica mais detalhada, o bebê aprende a expressar uma gama mais ampla de significados, ajudando a criança a desenvolver um complexo sistema conceitual de lemas.
Por volta dos quatro ou cinco anos de idade, os lemas da criança têm uma ampla gama de diversidade, isso as ajuda a selecionar o lema certo necessário para produzir uma fala correta. A leitura para bebês melhora seu léxico. Nessa idade, as crianças que foram lidas e são expostas a palavras mais incomuns e complexas têm mais 32 milhões de palavras do que uma criança que é linguisticamente empobrecida. Nesta idade, a criança deve poder falar em frases completas, semelhante a um adulto.